



PaLM’s performance demonstrates impressive natural language understanding and generation capabilities
One of the most dominant trends in AI, the infamous Large Language Model (LLM) comprises a massive set of neural networks possessing infinite potential. The larger a language model, the more information it can learn and process during training, making predictions better than traditional transformer models. Google’s new LLM, known as Pathways Language Model or PaLM, is a definitive result of the Pathways model – Google’s new AI architecture that aims to handle multiple tasks and learn new tasks quickly. An undertaking with highly ambitious goals, many aspects of PaLM still require further evaluation.
But does it represent a significant step forward for modern LLMs?
The alpha Megatron?
A new publication by Google outlines the workings of Pathways at every step of training PaLM. Other architecture versions include the PaLM 8B with 8 billion parameters, PaLM 62B with 62 billion, and PaLM 540B with 540 billion parameters. The idea of creating three different versions was to evaluate the cost-value function and the benefits of scale.
PaLM 540B is currently in the same league as some of the largest LLMs available today regarding the number of parameters; such as OpenAI’s GPT-3 with 175 billion, DeepMind’s Gopher and Chinchilla with 280 billion and 70 billion, Google’s GLaM and LaMDA with 1.2 trillion and 137 billion and Microsoft – Nvidia’s Turing NLG with 530 billion. The number of parameters present is significant in LLMs, although more parameters do not necessarily translate to a better-performing model. One of the first things to consider when talking about LLMs, like any other AI model, is the efficiency of the training process. In 2020, OpenAI proposed scaling laws to guide the training of modern LLMs. Recently, DeepMind published a paper named Training Compute-Optimal Large Language Models, in which analysts claim that training LLMs has always been done with a deeply suboptimal use of computing. Independently, Google reached similar yet better conclusions with PaLM.
PaLM’s training represents state-of-the-art on many levels. PaLM 540B was trained at the hardware level over two TPU v4 Pods connected over a data centre network (DCN) using the model and data parallelism. Google used a whopping 3,072 TPU v4 chips in each Pod, attached to 768 hosts, the largest TPU configuration ever attempted. This allowed it to efficiently scale training to 6,144 chips, achieving a training efficiency of 57.8 per cent hardware FLOPs utilisation, which Google claims is the highest yet achieved for LLMs at this scale.
Aid to LLM research
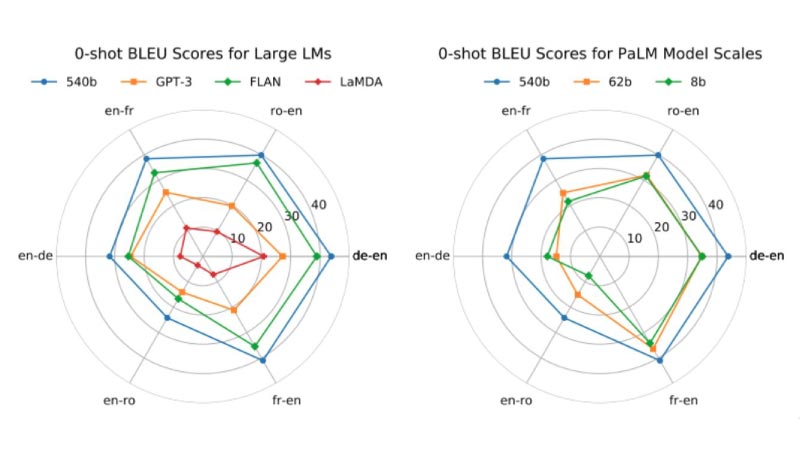
PaLM uses a customised transformer model architecture – an architecture used by all LLMs. Although PaLM deviates from it in some ways, more important is the focus of the training dataset used. PaLM’s performance, when compared against that of Gopher and Chinchilla, using the new Beyond the Imitation Game Benchmark (BIG-bench), demonstrates exceptional natural language understanding and generation capabilities. Tasks like distinguishing cause and effect, understanding conceptual combinations in appropriate contexts, and even guessing a movie from a combination of emojis were shown to perform better on the larger model. PaLM’s research proves that when model scaling is combined with chain-of-thought prompting, a wide array of reasoning tasks can be solved, an essential point of inspiration for modern LLM and NLP research.
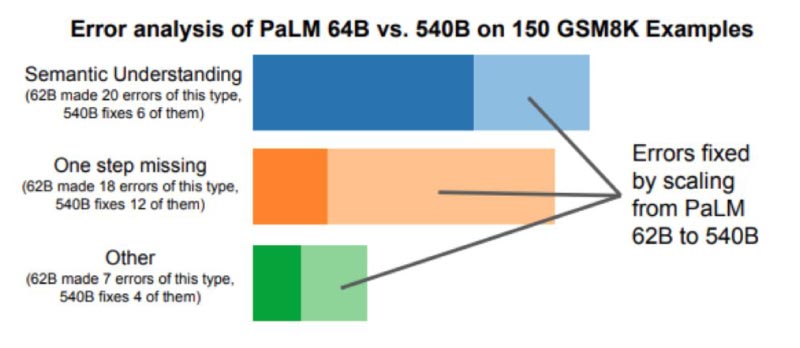
PaLM’s 540-billion model performed well at a range of tasks, including coding, where it was on par with OpenAI’s fine-tuned Codex 12B despite being trained on 50 times lesser Python code. At reasoning, PaLM solved 58 per cent of the problems in GSM8K, a benchmark dataset of tough school-level maths questions. The model beat the previous best score set by GPT-3’s 55 per cent.
Given PaLM’s bigger compute budget, the research proposed several theories that can aid modern LLM research. PaLM’s benchmark results proved that when a 540-billion parameter model is trained on 3 trillion tokens, it can result in state-of-the-art performance and be highly efficient for most inference tasks. Google’s BERT, one of the first LLMs, is still open source and has given birth to many variations in the LLM world. It even powered the latest incarnation of Google Search, and a hypothesis by several experts says that PaLM may eventually get on the same level too. As for the greater goal of human-level intelligence being achieved or not, opinions still may vary. Nevertheless, in areas where deep learning is being applied and tested, a plateau in performance seems to have been reached.
If you liked reading this, you might like our other stories
Can Project BigScience Leverage Large Language Models?
The Rise In Automation In The Middle East





