



Modern organisations are drowning in market intelligence. Or rather, market data in abundance is becoming intelligent, given the proper structure, inferences, and workflows.
An essential technology surfacing in the most advanced market intelligence-focused organisations is that of the automated knowledge graph. This article will examine why knowledge graphs are a natural “fit” for market intelligence and why automation is key to knowledge graph fact accumulation.
Market Intelligence is one of the oldest forms of commerce-related fact-gathering, and many of the fundamentals haven’t changed over time. This form of intelligence is primarily based on compiling information about the state of a market and its participants. In particular, information on customers, competitors, suppliers, and distributors.
This information is beneficial for sales and marketing, product development, and the investment of resources.
Historically, market intelligence has come from industry-specific data sources and physically observing market players without utilising the internet. However, today’s market companies and customers’ cohorts intelligence is primarily based online and is completed by analysing companies’ and customers’ cohorts. Think about all of the cues and data points one can gather about market players online.
- Reviews
- Product listings
- Product specs
- Press releases
- Regulatory announcements
- Hiring and firing trends
- New office openings
- News coverage of an industry
There are more than 200MM businesses with an online footprint, and those that matter most have a plethora of angles for online inquiry.
With this said, our first point can’t go unnoticed, while there’s no shortage of market data, organisations of all sizes wrangle with inefficiencies in transforming this data into intelligence.
Knowledge Graphs Excel At Market Intelligence
Knowledge graphs are built around the computing concept of graph databases. A graph database is composed of entities and connections. For example, an entity for Microsoft may have a relationship with the entity for Samsung. On the other hand, the relationship could be that of a supplier.
To a limited extent, one can think of graphs as relation-first databases. However, compared to relational databases, graphs exhibit many strengths, including flexibility and performance at scale.
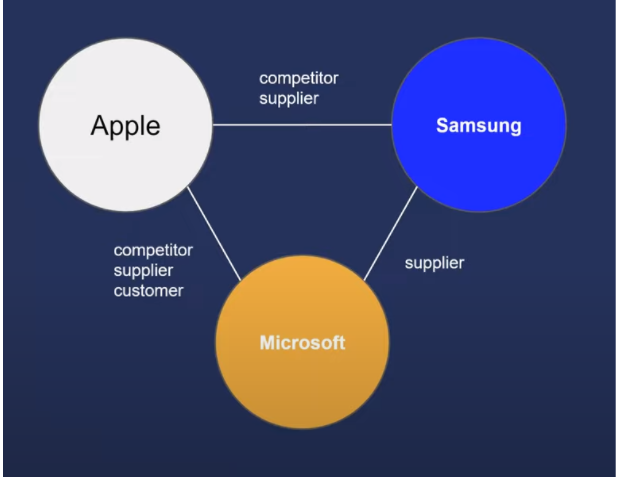
The first reason why knowledge graphs are great for market intelligence use cases is that entities are at the centre of both knowledge graphs and market intel. This is an essential observation as, at the end of the day, when performing market intelligence, analysts care about a given set of entities (be it their customers, suppliers, distributors, or competitors).
A corollary of this first reason is that knowledge graphs are an example of linked data. For example, a knowledge graph may contain an entity of “product” that includes a fact type of “manufacturer”. This manufacturer could be linked to an organisational entity. This allows for rich query ability (i.e. “return all data for article entities that are linked to organisation entities”) for a range of market intelligence uses.
The second reason why knowledge graphs are an excellent fit for market intelligence use cases is that knowledge graphs utilise flexible schemas. By schema here, we mean the structure of which facts and relationships are allowed and what entity type these facts and relationships are attached to.
Flexible schemas mean that the schema does not need to be defined in advance. This is particularly useful if the types of facts you care about change over time. For example, let’s say your knowledge graph comprises entities with a type “currency.” Perhaps one fact shared by all is an exchange rate and the number of units in circulation. But in the case of cryptocurrencies, a fact type that may matter could be that of “initial release” or a “ledger start date.” The ability to pull in new concepts or relationship types “on the fly” makes knowledge graphs resilient to ever-evolving business landscapes. This lack of rigidity in the schema allows for consistent evolution of up to date facts, entities, and relationship types within the knowledge graph.
A third reason why knowledge graphs are an excellent fit for market intelligence use cases is that knowledge graphs are masters of data integration. While knowledge graphs can provide great flexibility through linking new facts and relationship types to entities, each entity still has a unique resource identifier. This identifier allows easy access to internal data stores, other external data sources, or future data updates. This linking of sources and data stores is the essence of market intelligence. In addition, disambiguation is particularly useful for person entity data, where many individuals may have identical names.
Also Read: Key Digital Marketing Trends to Watch for in 2021
Automated Knowledge Graphs Key For Market Intelligence
Historically, market intelligence has primarily occurred through human insight and observation. But with the emergence of globally interconnected markets and publicly accessible customer interaction data, manual research simply can’t keep up.
The inability to effectively scale human fact curation leads to the first reason automated knowledge graphs are crucial: market intelligence applications are sensitive to stale data.
Few market intelligence data sources are ever truly “live” (think sensor or stock data), but from the moment market intel data is encoded in a database, it’s subject to becoming stale. Stale data is problematic because it may become inaccurate or miss out on supporting actionable analyses and because stale data gives the illusion that you have data coverage. Where incomplete or missing data may simply be skipped in an analysis, the delusion that accurate stale data can support wrong conclusions.
For accurate market intelligence, it is not sufficient to assemble facts on a one-time basis within a database but requires updates on an automatic and recurring basis. In market data, elements such as the date or the minute a fact is reported are relevant for real-time knowledge. Human curation doesn’t scale this information in the same way that automated knowledge graphs eCommerce
Also Read: What is Graph Data Science? And Why Does it Matter?
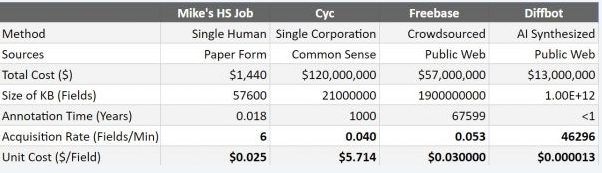
(Source: “The Economics of Building Knowledge Bases”)
In the image above, we look at a variety of fact accumulation methods, including the high school data entry job of Diffbot CEO Mike Tung.
Of note, the most extensive human-compiled knowledge base, Freebase, still doesn’t lower the cost of fact accumulation than traditional manual data entry. This means that while Freebase is likely the best example of a large number of human-curated fields, the only way to scale this effort further is to spend more and recruit more curators.
Truly automated knowledge graphs utilise machine vision and natural language processing (NLP) to accumulate facts like humans, but much more quickly.
A second reason why automation in knowledge graphs is critical is that today market signals can come from anywhere. Nearly every market is international or at least supplied by international organisations. Market signals can come from a vast, dramatically significant variety of locations online, everything from databases of patent filings to job boards, eCommerce reviews, product inventory, and news articles. Not even exceedingly large teams of manual fact gatherers can keep tabs on the number of languages or locations online where prescient market intelligence could surface.
Knowledge graphs that can accumulate facts from the public web have an inherent advantage in terms of data coverage and freshness in this regard. Furthermore, machines that read and structure the web can do so 24/7/365 and at much faster rates than human fact accumulation.
Conclusion
Today, market intelligence signals occur with much greater velocity and from many more sources than ever before. While many facts are publicly available on the web, few human teams can keep up with curating facts from even a handful of sites. Automated knowledge graphs are well suited for dealing with this velocity and variability in fact types and locations. Flexible schemas allow for the ability to add new fact types “on the fly.” A focus on accumulating facts and relationships about entities provides various“views” into data that matters in market intelligence. Finally, knowledge graphs that can leverage AI-enabled web scraping, fact accumulation, natural language understanding, and fact linking can scale much more affordably than any human team.
Mike Tung is the CEO of Diffbot, an adviser at the Stanford StartX accelerator, and the leader of Stanford’s entry in the DARPA Robotics Challenge. Earlier, he was a software engineer at eBay, Yahoo and Microsoft. Tung studied Electrical Engineering and Computer Science at UC Berkeley and Artificial Intelligence at Stanford.





