



Prior research suggested that networks should only need to be a specific size, but modern neural networks today are scaled up far beyond the predicted requirement
The use of neural networks is the leading artificial intelligence (AI) system, aiding to perform human-like tasks. Furthermore, as they have gotten bigger, they have come to grasp more. This has been a surprise. Prior fundamental mathematical results through research had suggested that networks should only be a specific size, but modern neural networks are scaled up far beyond the predicted requirement, such a situation is known as over-parameterisation.
In a paper recently presented at the leading conference NeurIPS, Sébastien Bubeck of Microsoft Research and Mark Sellke of Stanford University explained the mystery behind the scaling method’s success. They found that neural networks must be much larger than conventionally expected to avoid specific fundamental problems. The findings also offer a general insight into a question that has persisted over several decades – the deeper the neural network, the better?
The essence of big networks
The standard expectations for the size of a neural network come from how they memorise data. However, to understand memorisation, we must also correctly understand what these intricate networks do. A common task for neural networks is identifying objects in images. To create a network, researchers first provide several images and object labels, training it to learn specific correlations between them. Afterwards, the network correctly identifies the object in an image it had already seen. In other words, training causes a network to memorise data. Once a network has learned enough training data, it can predict the labels of objects it has never seen, even up to varying degrees of accuracy.
An essential property that most neural networks often lack is called robustness, i.e., the ability of a network to deal with minor changes. For example, a network that is not robust may have learned to recognise a giraffe, but it would at times tend to mislabel a slightly modified version of the image as a gerbil. In 2019, Bubeck and colleagues sought to prove theorems about the problem when they realised it was connected to a network’s size and determined that the network’s size determines how much it can memorise. Therefore, it can be said that over-parameterisation is necessary for a network to be robust.
Other research has also revealed additional reasons why over-parameterisation is helpful. For example, it can improve the efficiency of the training process and the ability of a network to generalise. While we now know that over-parameterisation is necessary for robustness, it is unclear how necessary robustness is for other things. Nevertheless, by connecting it to over-parameterisation, the new proof hints that robustness may be more important than was thought, a single key that unlocks many benefits.
The other side of big networks
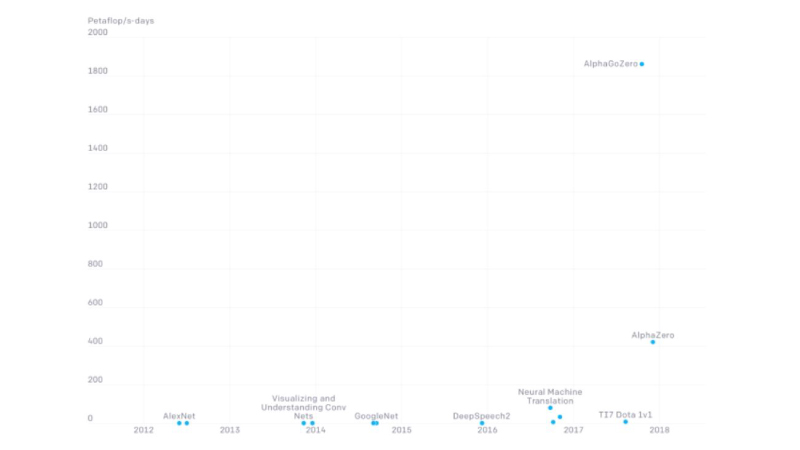
The most significant implication of bigger neural networks is the financial costs of training AI models created using deep networks. According to a chart published by OpenAI on its website, it took more than 1,800 petaflop/s-days to train AlphaGoZero, i.e., DeepMind’s historic Go-playing AI. A Google TPU v3 processor, specialised for neural tasks, performs up to 420 teraflops and costs $2.40-8.00 per hour. It costs around $246,800-822,800 to train the AlphaGoZero model, just the compute cost.
According to figures released by DeepMind for its StarCraft-playing AI, the model consisted of 18 agents, and each agent was trained with 16 Google TPUs v3 for 14 days. The company spent about $774,000 for the 18 AI agents it trained. The compute requirements of deep learning and neural networks research pose another set of severe constraints. As per the current trends, due to the costs of research, especially reinforcement learning, several well-known research labs are becoming increasingly dependent on wealthy companies such as Google and Microsoft.
According to a paper published by researchers at the University of Massachusetts Amherst, training a transformer AI model (often uses deep neural networks) with 213 million parameters causes as much pollution as the entire lifetime of five vehicles. The environmental concern will only worsen because the current research is primarily dominated by the “bigger is better” mantra. Unfortunately, researchers often pay attention to these aspects during their extensive work. Researchers from the University of Massachusetts recommend that AI papers be more transparent about the environmental costs of their models and provide the public with a better picture of the implications of their work.
One of the most exciting works done recently is the ongoing research for the development of hybrid AI models that can combine neural networks and symbolic AI. Symbolic AI is a classical and rule-based approach to creating intelligence.
Unlike neural networks, symbolic AI does not scale by increasing compute resources and data. Although processing messy, unstructured data is not up to the mark, it is terrific at knowledge representation and reasoning – the two areas where neural networks lack sorely. Exploring hybrid AI approaches might open new pathways for creating more resource-efficient AI. It should not take another winter for the data science community to start thinking about finding optimal ways to make neural networks more resource-efficient.
If you liked reading this, you might like our other stories





