



A data mesh is more than technical architecture. It’s a way to organise around data ownership and its activation
![]()
Data platforms today appear to be centralised, monolithic, and domain agnostic. Traditional platforms often take the form of proprietary enterprise data warehouses with thousands of unmaintainable ETL jobs, tables, and reports that only a small group of specialised people understand. This results in an under-realised positive impact on the business, or complex data lakes operated by a central team of hyper-specialised data engineers that create pockets of R&D analytics.
Hence, there seems to be a need for a domain-driven design that enables the modern data stack to achieve a balance between centralisation and decentralisation of metadata and data management. A data mesh intends to offer a solution to such issues.
What is a data mesh?
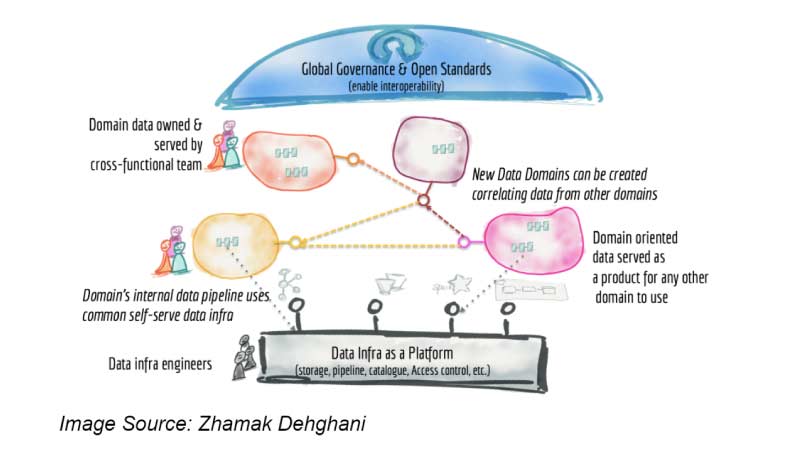
Data mesh originates from a paper authored in May 2019 by Zhamak Dehghani, where she mentions that “Data platforms based on the data lake architecture have common failure modes that lead to unfulfilled promises at scale. To address these failure modes, we need to shift from the centralised paradigm of a lake or its predecessor data warehouse.” A data mesh platform is an intentionally designed distributed data architecture under centralised governance and standardisation for interoperability, enabled by a shared and harmonised self-serve data infrastructure.
A data mesh is more than technical architecture; it is organised around data ownership and activation. The data mesh becomes the foundation for a modern data stack that rests on six fundamental principles when successfully deployed.
For your data mesh to work, data must be:
- discoverable
- addressable
- trustworthy
- self-describing
- inter-operable
- secure
How does it operate?
The data mesh needs a data foundation to operate successfully; this prior stage is to create a data ocean. A data ocean is more comprehensive than a data lake, as it is focused on securely providing complete visibility to the entire data estate available to data teams to realise their potential, without necessarily moving it.
Nevertheless, while the data ocean is the architectural foundation required to set your data mesh up for success, the data mesh itself is an organisational model that enables your team to build data products. Data mesh extracts domain-agnostic data infrastructure capabilities into a central platform that handles the data pipeline engines, storage, and streaming infrastructure. Meanwhile, each domain is responsible for leveraging components to run custom ETL pipelines, giving them the support necessary to efficiently serve their data and the autonomy required to own the process truly.
Advantages of data mesh
A data lake can fall short in a few ways. A central ETL pipeline gives teams less control over increasing volumes of data, and as every company evolves towards becoming a data company, different data use cases require different types of transformations, putting a heavy load on the central platform. Such data lakes lead to disconnected data producers, putting data consumers in peril, and a data team struggling to keep pace with the demands of the business. Instead, domain-oriented data architectures like data mesh provide organisations with the best of both worlds – a centralised database (a distributed data lake) with domains (business areas) responsible for handling their pipelines.
With the number of data sources growing every day, many organisations are now considering their options for scaling. Data mesh is a good fit if you are focused on domain-driven development, started working with microservices, or if your organisation does cloud migration. Although data mesh is not the only option for scaling to many teams, companies with sufficient capabilities to coordinate data management can keep a centralised data platform and avoid the overhead of decentralisation.
However, implementing a data mesh allows for more accessible data architecture scaling by breaking them into smaller, domain-oriented components.
If you liked reading this, you might like our other stories
How CSPs Are Now Using Blockchain
Build A Strong Data Protection Strategy In 10 Steps





