



The company, previously criticised for several concerns regarding identifying harmful content and algorithmic bias, is now confident that the RSC’s advanced capabilities will help address them.
Meta (formerly Facebook) announced in January that it is developing a supercomputer known as the AI Research SuperCluster (RSC) and claims that once completed by the end of the year, it promises to be one of the world’s fastest AI supercomputers.
CEO Mark Zuckerberg also stated that the experiences the company is building for the metaverse require enormous computing power, reaching into quintillions of operations per second. Thus, the RSC will enable new AI models to learn from trillions of examples, understand hundreds of languages, and more.
The company was previously criticised for several concerns, such as identifying harmful content and algorithmic bias but now is confident that the RSC’s advanced capabilities will help address concerns. However, is it really what Meta claims? What does such a development mean for the future of AI?
The Claim
Keeping in mind prior reported concerns, Meta explained in a blog post how it plans to safeguard the privacy of user data that this AI-powered RSC will be trained on. Specifically, the company highlighted the fact that “RSC is isolated from the larger internet, with no direct inbound or outbound connections, and traffic can flow only from Meta’s production data centres.”
According to Meta, before data is imported to RSC, it goes through a privacy review process to confirm it is correctly anonymised, or alternative privacy safeguards have been put in place to protect the data.
The data is then encrypted before it can be used to train AI models, and both the data and the decryption keys are deleted regularly to ensure older data is not still accessible. Moreover, as the data is decrypted only at a single endpoint in memory, it is to be safeguarded even in the unlikely event of a physical breach of the facility.
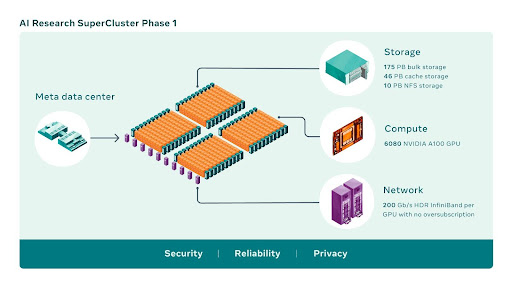
RSC’s Potential
RSC supercomputer shows immense technological potential and opportunity, including targeting hate-driven content within all the scepticism. In 2020, the company shared that 97 per cent of hate speech taken down from Facebook was spotted by its in-house automated systems before any human flagged it. The issue of harmful content became a matter of grave concern during the election misinformation in 2016 and 2020, and it is a priority Meta assures they are working on.
Since the RSC will aid AI models to learn from trillions of examples and understand hundreds of languages, its design is focused more on tackling goals like targeting hate speech and harmful content more quickly and thoroughly utilising the vast computing power.
“While the high-performance computing community has been tackling scale for decades, we also had to make sure we have all the needed security and privacy controls in place to protect any training data we use.
Unlike with our previous AI research infrastructure, which leveraged only open source and other publicly available data sets, RSC also helps ensure that our research translates effectively into practice by allowing us to include real-world examples from Meta’s production systems in model training,” Meta elaborated in the announcement about RSC’s capabilities.
Data storage company Pure Storage and chip-maker Nvidia are also part of Facebook’s supercluster. Mainly, Nvidia is a key player supporting the metaverse, with its omniverse product billed as “metaverse for engineers.”

The RSC will help Meta’s AI researchers build new and better AI models that can learn from trillions of examples and enable work across hundreds of different languages, analyse text, images, and video together seamlessly, and develop new augmented reality tools. The resource enables Meta’s researchers to train the most significant models to develop advanced AI for computer vision, NLP, speech recognition.

Looming Problems Still?
Meta’s new AI-powered supercomputer might just still be ethically problematic in ways related to privacy. The type of privacy protection, which Meta calls “functionally protecting”, is not entirely what it sounds like – not inherently protecting user data.
Will they genuinely anonymise the data? A problem with large tech giants has always been the lack of transparency with publicly defining what they mean by “anonymised data” and how they define the who and what analysis takes the place of that user data.
Data can be de-anonymised depending on surrounding factors, if there are inherently unique qualities within a person’s data that are known or can reasonably be inferred through another context, then that data becomes de-anonymised to someone based on that information.
Anonymous data cannot be used to identify a specific individual, but certain AI research is not possible to perform with anonymised data (e.g., speech recognition), was Meta’s shared statement related to data anonymity and the RSC.
Numerous AI and privacy experts have already raised concerns related to privacy and security of RSC’s current calculations and data and Meta’s privacy protocols and safeguards, as Meta’s current policy appears to lack explicit details around what happens when, inevitably, there is a mishap with user data with the RSC.
Nevertheless, RSC seems to be paving the way toward building technologies for the next central computing platform, the metaverse, where AI-driven applications and products will play an important role.
RSC surely can inspire others to build entirely new AI systems that can power large groups of people to seamlessly collaborate on a research project or play an AR game together.
Ultimately, the further work done with RSC will help create the foundational technology blueprint that can transform the metaverse and further advance the AI community across industries.
If you liked reading this, you might like our other stories
Privacy Dynamics Launches One-Click De-Identification Tool
February Round-Up: All The Tech News You Need To Know





